
What is a Schema?
A schema is a collection of database objects that include views, indexes, tables and synonyms. The schema is designed based on the requisites of the project. The star schema, snow flake schema, galaxy schema, and fact constellation schema are the main schemas according to which a data warehouse can be designed.
Dimensions
A dimension table consists of two columns, primary keys referencing the fact table and textual or definitive data. The dimensions are listed below:
Slowly Changing Dimension
The attributes of a dimension change according to time. The change is captured based on the requirements of the business. This is called a slowly changing attribute and the dimension consisting of such an attribute is known as a slowly changing dimension.
Junk Dimension
A dimension consisting of various unrelated attributes is a junk dimension. This is created to prevent a large number of foreign keys in a fact table.
Inferred Dimension
A dimension record might not be available or ready when loading a fact. This can be solved by generating a surrogate key with Null for all the other attributes. This attribute is regarded as an inferred dimension
Conformed Dimension
A dimension used across several fact tables in a database is known as a conformed dimension. For example, date dimension is used across several facts.
Degenerate Dimension
A dimension where the dimension attributes are stored as part of a fact table and not in a separate dimension table is known as a degenerate dimension. These dimension keys generally do not have any attributes.
Facts
Facts consist of measures that are numeric values and additive or semi-additive in nature.
Additive Facts
Facts that can be aggregated through all the dimensions in a fact table are known as an additive fact.
Semi-Additive Facts
Facts that can be summed up for some of the dimensions in the fact table but not the others are semi-additive facts.
Non-Additive Facts
A fact that cannot be summed up for any of the dimensions present in the fact table is a non-additive fact.
Factless Fact
A fact that contains no measures or facts is known as a factless fact table.
Normalization and Denormalization
Normalization
- Normalization is a process implemented to minimize the redundancies or the repetition of data present in a database
- The process involves dividing the larger tables into smaller tables with lesser redundancies
- The smaller tables are interrelated to each other through well-defined relationships
Denormalization
- Denormalization is the converse process of normalization.
- The process involves adding redundant data or grouping data to enhance the performance
- Adding redundancies might seem to be a contradictory act, but joining several tables when executing a query (caused by normalization) might slow-down the database performance
Star Schema
Star schema is one of the simplest schemas in a data warehouse.
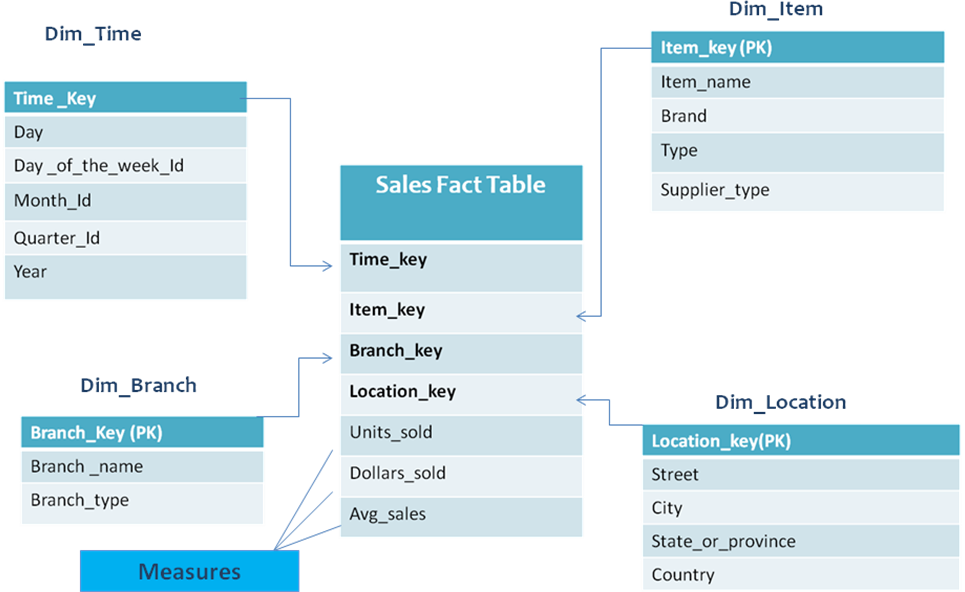
- A star schema has each of the dimensions represented in a single table. There are no hierarchies present between the dimensions
- Consists of a single fact table surrounded by dimension tables. The dimensions are denormalized
- There is only one join between the fact table and any one of the dimension tables
- Called a star schema because the diagram represents a star
Advantages of a Star Schema
- It has a high point of traceability and comprehensibility
- The data can be navigated easily. A single dimension table can be browsed to select the attributes to construct a query
Disadvantages of a Star Schema
- Redundancy in a dimension because of multiple storage of similar data
- A slower response in the query time due to the large dimension tables
Snow Flake Schema
A snow flake schema is complex data warehouse model than a star schema.
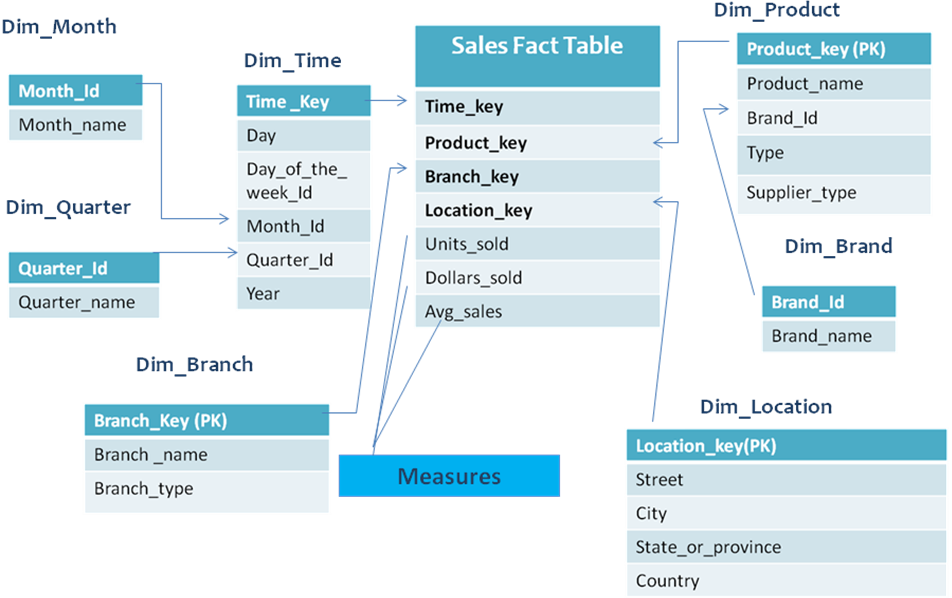
- A snow flake schema consists of at least one hierarchy among the dimension tables
- It consists of a fact table surrounded by dimension tables
- The dimension when normalized in a schema is known as a snow flake
- The snowflake schemas normalize dimensions to eliminate redundancy
Advantages of a Snow Flake Schema
- The normalized structures are easier to maintain and update
- Small savings in storage space
Disadvantages of a Star Schema
- Complexity of the schema does not seem user-friendly for the end users
- The navigation through the tables is difficult
Fact Constellation Schema
The fact constellation schema is an extension of a star schema.
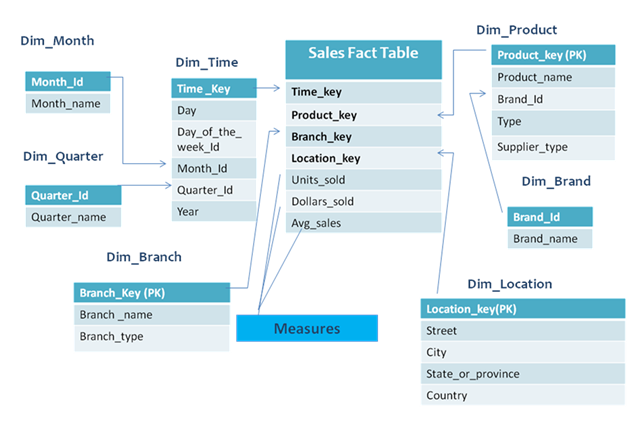
- The more refined applications may need multiple fact tables to share dimension tables.
- Different fact tables are explicitly assigned to the dimensions. This is advantageous for facts associated with a given dimension table and other facts with a deeper dimension level
- This schema resembles a collection of stars, and hence is called a galaxy schema or a fact constellation
Advantages of a Fact Constellation Schema
- Provides a flexible schema for implementation
Disadvantages of a Fact Constellation Schema
- Complexity of the schema involved because of several aggregations
Surrogate Keys
Surrogate keys are integers that do not have a specific meaning in terms of business and used a primary key in a dimension table. It is because of this reason that surrogate keys are often known as meaningless keys
The efficient practice in a data warehouse is to join the dimension table to a fact using only a surrogate key and not a business key
Why do we need a surrogate key?
- A primary key in a dimension is generally alphanumeric like ABF635 which occupies lot of index space. This slows down index traversing
- Business keys are reused in a data warehouse. Maintaining versions becomes difficult when reusing the business keys
Benefits of a surrogate key?
- Surrogate keys are smaller integer numbers, hence they occupy a smaller index size
- Using surrogate keys can make dimension table handle the changes in it effectively. In cases where the business keys are reused surrogate keys act as a unique identifier
Slowly Changing Dimensions
Slowly changing dimensions determine how the historical changes in a dimension table are handled. Enabling a slowly changing dimension allows users to know which category of an item belongs to which date.
For example, people change their name due to several reasons. In order to know their names during a specific period of time we need to incorporate a slowly changing dimension
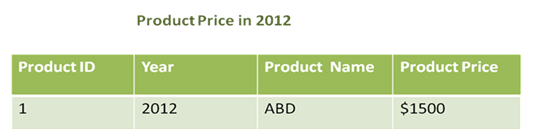
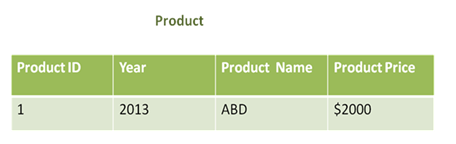
Type 1 Slowly Changing Dimensions
- Type 1 SCD is used when there is no need to maintain history in the database
- The new, changed data overwrites the old entries. This method is used for data that changes frequently due to misspells, trimming spaces and language specific characters
- The data is easier to maintain
For example, in the year 2013 the price of the product changes to $2000, then the values of the product price and year needs to be updated to the new values.
There is now way to find the rate of the product in the year 2012 since the values are over written as illustrated below
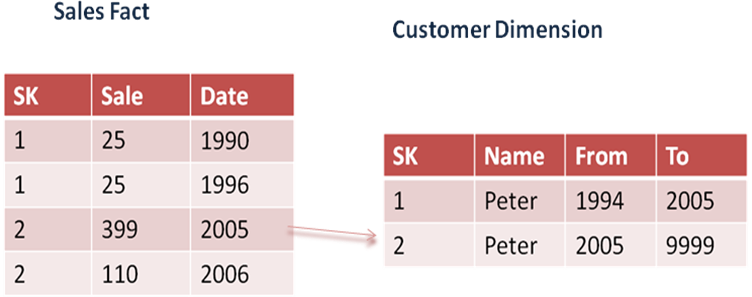
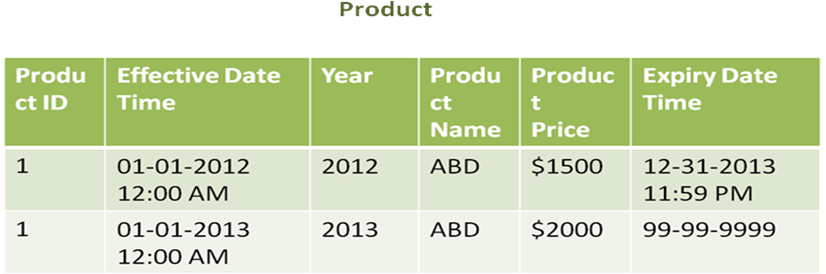
Type 2 Slowly Changing Dimensions
- Type 2 SCD is used when there is a need to maintain the complete history in the database
- An additional dimension record is created and the segmentation between the old record values and the new values are easier to extract
For example, in the table below the product id and the effective date time act as composite primary keys. Hence, there is no violation of the primary key here. Moreover, the product’s effective date time and expiry date time adds more clarity and improves the scope of the table
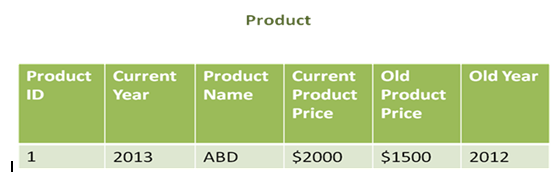
Type 3 Slowly Changing Dimensions
- Type 3 SCD is used when there is a need to maintain the partial history in the database
- An ‘old’ or ‘new’ column is created that stores the immediate previous attribute. This is the least commonly used technique
For example, the latest update to the changed values can be seen. A new column is added to track the changes. We can see the current and the previous price of the product
Role of SCDs in a Data warehouse
- The techniques discussed above can impact the data warehouse profoundly, both physically as well as logically
- The data warehouse architect has to analyze each particular scenario and decide the most efficient way to implement them
- The type 2 technique is the most frequently used in a data warehouse. Managers and business analysts would always be interested in the whereabouts of the information. The types 2 provides this data that is critical for making important decisions