
2.1 Hadoop Block
While processing a file in Hadoop ecosystem, it gets converted into a block or gets split into multiple blocks depending upon the size of the file. Each block is made up of a default size of 64 MB.
Below diagram explains how a file of 512 MB is gets split into 8 different blocks
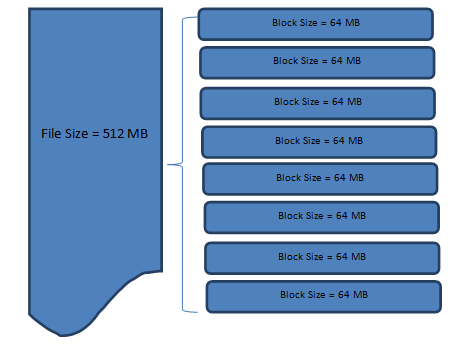
Here the file that comes for processing has a size of 512 MB. So, Hadoop will convert it into 8 different blocks, each with 64 MB size (In this example we have kept the default block size which is 64 MB). Now instead of this file, 8 different blocks would be processed by Hadoop.
Now question comes - what happens when your file size is less than block size?
Here is the answer:
Hadoop utilizes its resources based on the size of the file (remember it is Best for Big Data), however when a file comes for processing that has a size less than the assigned block size, then it will get processed in a single block. It has following drawbacks:
- The block would be processed but with having a portion as empty and the remaining capacity of the big block would turn out to be a big waste.
- If we have lot of small size files, then lot of latency would be introduced in the system as Hadoop will take time to process the entire block. Now you can notice what we mentioned in the 1st chapter - that Hadoop processing is good when you have large data in a single file and not when you have large number of files but with smaller data in it.
- Another issue is that Name Node stores meta data information (block information, where a particular block is allocated) for every block and if lot of small files get processed then each time meta data information would be captured and the size of metadata information would go on increasing.
So, how to deal with this kind of situation?
Answer is to modify the default block size as per the size of file. In this case we could lower down the size from default value 64 MB to something else.

Block Replication
Hadoop system runs over the cluster of commodity computers (Known as Data Nodes) and when any of these Data Nodes fail, we are going to lose the data that is on that particular machine.
In order to overcome this problem, Hadoop has a mechanism of Block replication among the Data Nodes. This means that the data that is available in one machine would get replicated and available on other machine as well. This will assure data availability all the time. The default replication factor is 3; this means that at any particular point of time there would be as many as 3 copies of the same data that would be available in the cluster of Hadoop.
Now, One can think that by replicating same data we are introducing redundancy in the system. Definitely we are adding additional burden in the system by carrying same data over and over again. But think this way that, we took care of Node failure issue and most importantly we have saved the data. If we lose data then sometime you need to waste a lot of time and resources in getting back that data.
2.2 Hadoop Rack
Rack consists of sequence of Data Nodes. Single Hadoop cluster may have one or more Racks depending on the size of the cluster. Let us understand how the Racks are arranged for small and large Hadoop cluster.
Small Cluster
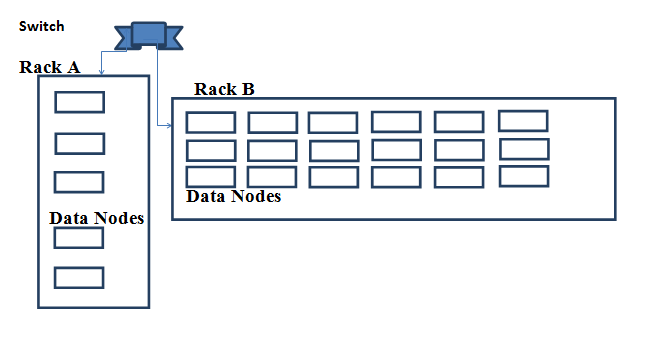
This is a Hadoop cluster which is considerably small in size where all machines are connected by a single switch. In this type of cluster, we normally have a single Rack. For Block Replication (where Replication Factor = 3), first the Name Node copies data to one Data Node and then other two Data Nodes get selected randomly.
Larger Clusters
This Hadoop cluster involves many Data Nodes and is of the bigger size. And these different Data Nodes are scattered over many Racks. While implementing Block Replication (where Replication Factor = 3) Hadoop will make first copy of Block at one of the nearby Racks and then place the other two copies of Blocks on other Rack (on two different Data Nodes at random). Here in this scenario our data is available on two different Racks.
We have taken care of two things –
- Data Node Failure
If any of the Data Node goes down then data would be available in other two Data Nodes.
- Rack Failure
In this case if one of the Racks (Even the Rack with two Data Nodes) goes down then our data would be available over other Rack (With one Data Node).
In both the scenarios our data is safe and it will continue to ensure availability.
2.3 Hadoop NameNode
NameNode is the main central driving component of HDFS architecture framework. It is a Master node, keeps a track of files assigned to Data Node.
Its Major Responsibilities include:
To maintain the file structure in the file system
Keeps track of which file is located where in the cluster. When a file is processed in the form of several Blocks then Name Node knows the exact position of Block in the Hadoop cluster i.e. among the Data Nodes.
Take care of communication with Client Application
Client application sends a request to Name Node to perform some file related operation such as add, move, copy or delete. Then Name Node responds to the requests by returning a list of appropriate Data Nodes wherever data particular to that file is available.
Update the Meta data table when Data Node fails
Upon failure of a Data Node it is the responsibility of Name Node to replicate blocks (those that were running on that particular failed node) to some other Data Node available in Hadoop cluster. After that, it updates the Meta data information.
Two different types of information it updates
- First it maintains the information of Block associated with a file i.e. which Block maps to which file.
- Second information is which Block available in which Data Node.
The Name Node is a Single Point in Hadoop that means whenever Name Node goes down we lose all information available in it. We have something known as Secondary NameNode that was not the backup (Standby) of the Name Node. It only created checkpoints of the namespace. This was the configuration available before Hadoop 0.21 version, but after that we have Backup NameNode that is the mirror image of Name Node and can act as Name Node in the cases when actual Name Node goes down.
Some best practices with Hadoop NameNode
- Hardware specification has to be very good.
- Store multiple copies of Meta data by having more than one Name Node directory. It is best to have these directories on separate disks so that in the event of disk failure Meta data would not be lost.
- Add storage whenever free space available on disk of Name Node goes lower.
- Try to avoid hosting Name Node and JobTracker on the same machine.
2.4 Hadoop DataNode
Data Node is the component where actual data processing and execution takes place. We have already seen that these are normally commodity computers where actual data gets stored.
Its Major Responsibilities include:
Update to Name Node with their live status
Every Data Node sends a heartbeat message to the Name Node every 3 seconds and conveys that it is alive. In the scenario when Name Node does not receive a heartbeat from a Data Node for 10 minutes, the Name Node considers that particular Data Node as dead and starts the process of Block replication on some other Data Node.
Synchronization among Data Nodes
All Data Nodes are synchronized in the Hadoop cluster in a way that they can communicate with one another and make sure of
- Balancing the data in the system
- Move data for keeping high replication
- Copy Data when required
Verification of data
Data Node stores a Block and maintains the checksum for it. Data Node is accountable for verifying the data even before storing it and its checksum. A client writes data and sends it to cluster of HadoopData Nodes and the last Data Node in the pipeline verifies the checksum.
The Data Node updates the Name Node with the Block information at a regular interval of time. If the checksum is not correct for a particular Block in the event of some failure then Data Node does not report that particular Block information to the Name Node.
Client does a checking and when Blocks do not match with their available checksum then it will request the same Block from another Data Node which has a replication copy of that Block.
Let us see some hardware configuration scheme for a Data Node
- Hard Disk (15-20)- 1-5TB
- Processor- 2-2.5GHz
- RAM - 64-512GB
- If you want more throughput then better go for a higher storage, recommended 8-10 GB Ethernet
2.5 Hadoop Job Tracker
Apart from Master Slave relationship of Name Node and Data Node there is one more relation of the same kind in the Hadoop eco system and it is between Job Tracker and Task Tracker where Job Tracker acts as a Master and Task Tracker acts as Slave. If you notice then you will find Name Node and Data Node are responsible for majorly file management while here Job Tracker and Task Tracker are responsible for resource management.
Job Tracker manages the Task Trackers and tracks the resource availability, progress of submitted Job and any occurring fault tolerance in the system.
JobTracker receives requests from client and assigns this request to Task Trackers with the information of the tasks to be performed. While assigning task to Task Tracker, the Job Tracker first checks for Data Node in following order
- Initially checks and assigns to a TaskTracker that is available locally in the Cluster.
- Otherwise it assigns to the Task Tracker on Data Node that is available in the same Rack.
- Finally if both the above mentioned two cases are not possible then it assigns to a Data Node in different Rack.
In the event when Data Node fails, then Task Tracker assigns the task to other Task Tracker where the replica of the same task exist. This will any how make sure that the task is going to be completed.
2.6 Hadoop Task Tracker
Task Tracker follows the order received from Job Tracker and its major responsibility is to update the Job Tracker with the progress of the Job being run. We have a WEB interface available in Hadoop ecosystem through which the current status and all information about the Job Tracker and the Task Tracker can be seen.
Let us try to understand all its functioning in more detail –
- The Task Tracker sends continuous heartbeat messages to Job Tracker to inform its live status. Task Tracker also updates with the available empty slots for running additional tasks.
- The Task Tracker assures not to get down by spawning various JVM processes.
- All the empty slots available in Task Tracker indicate the number of tasks that it can accept.
2.7 Map Reduce
MapReduce programs are the core of Hadoop eco System built to compute large volumes of data in a parallel manner across cluster of computers. The basic feature of Map Reduce paradigm is to divide the task among various Data Nodes to perform execution on these Data Nodes and then in return collect the output from all these Data Nodes. The first part where we divide the task across cluster of computers is known as Map while getting the output and collect it back is known as Reduce.
Let us understand it with this example, suppose we have three files with data as –
File1 – This is my Book
File2 – I am reading a Book
File3 – Book is a good source of knowledge
The task is to collect the frequency of word present in all three files combined
So, output should be –
This | 1 |
Is | 2 |
My | 1 |
Book | 3 |
I | 1 |
Am | 1 |
Reading | 1 |
A | 2 |
Good | 1 |
Source | 1 |
Of | 1 |
Knowledge | 1 |
Let us execute this task in Hadoop ecosystem. Assume we have three different instances of Data Nodes running in our cluster. All three files would be executed in three different Data Nodes. A Mapper program will be responsible for taking the frequency word count from each individual Data Node. And a Reducer program will be responsible for collecting frequency statistics from each individual Data Node and after that perform aggregation by doing sum of count for each word group.
After doing this exercise we should receive output mentioned in the table.
Let us see below diagram and understand Map Reduce Paradigm
Map

Reduce

2.8 Hadoop File system (HDFS)
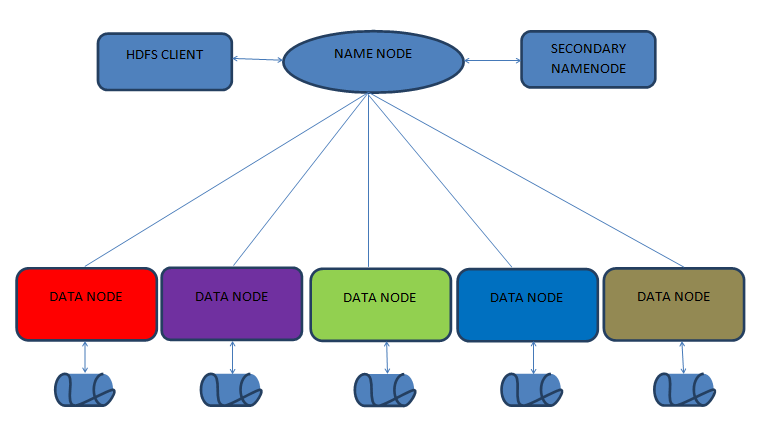
HDFS is Hadoop distributed file system. HDFS defines the way the storage will take place. HDFS is built to yield maximum throughput. Its efficient performance seen while working with large data sets.As we have already mentioned that HDFS is Highly Available and Very Scalable. We have also seen how by utilizing the concept of replication, it is fault tolerant. The effective Map Reduce paradigm boost its capability of high end distributed computing in a parallel environment. Below diagram shows how various components of HDFS are connected and work as a single massive unit.
Name Node and the Job Tracker get list of all rack ids associated with their Slave Nodes. By using this information HDFS creates a mapping between IP address and received rack id. HDFS applies this knowledge for Block replication over different racks.
Hadoop does one more thing very intelligently and that is identifying the performance of Data Nodes. If it identifies slowness of any Data Node while execution, then it immediately runs the same redundant job on a different Data Node. So, now the same task is being run over two different Data Nodes. Here whichever Data Node’s task gets completed first that gets reported to Job Tracker.
We have already understood Hadoop architecture and now it is the time to start doing some visualization of Hadoop.