
8.1 What is Sqoop
Sqoop is a utility built up in Hadoop to perform data transfer between Hadoop and relational database management system. Sqoop is used to import the data from a RDBMS into the Hadoop Distributed File System then transform the data in Hadoop by executing MapReduce job and ultimately export the data back into an RDBMS. HDFS is capable of large data processing, it handles both structured and unstructured data. Hadoop has its own database as HBase for the data store and retrieval. Sqoop is able to perform data link and communication between Hadoop and structured data store. Sqoop can very well automates this process, it relies on the database to describe the schema for the data to be imported. Sqoop can effectively uses the MapReduce operations to import and export the data, which provides parallel execution along with the fault tolerance.
8.2 Sqoop Installation and Configuration
Sqoop can be downloaded from Apache website. If it is downloaded from Apache website then it will be placed in the directory like
- /home/<<yourname>>/<<sqoop>>/
- We will assign this directory as $SQOOP_HOME
- A very simple way to run Sqoop is like %sqoop
- Sqoop has lot of commands and tools associated with it. Help is tool in Sqoop that can in list all the available tools in Sqoop so that we can use it accordingly.
- %sqoop helpIf you want to explore the detail information to check the detail for a particular tool then we can do it using %sqoop help <<tool name>>
8.3 Understand the Basics of Hadoop
Sqoop Connector
As we understand now that Sqoop has a framework that let us allow, with bulk data transfer capabilities, transfer data by doing import data from other data store and export data to other external storage system. Sqoop is able to perform this import and export in the framework with the help of a modular component that is known as the Sqoop Connector. Sqoop uses these connector to establish a connection with variety of relational databases including Oracle, DB2, MySQL, SQL Server and PostgreSQL. There is also a JDBC connector for connecting to a database that supports Java’s JDBC protocol. Sqoop also provides connectors for MySQL and PostgreSQL that is much optimized. It also provides APIs that is specific to particular database and performs bulk data transfer efficiently. Along with the Sqoop built in connectors there are some third party connectors are also available for data stores like enterprise data warehouses (Oracle, Teradata, Netezza) and for NoSQL database (like Couchbase). We can download these connectors separately and can add to the existing Sqoop installation.
As we know that Hadoop is written in JAVA and on the same line Sqoop is also implemented using JAVA. JDBC (JAVA Database Connectivity), an API of JAVA, allow accessing RDBMS stored data to the applications. JDBC also has the capability to do an inspection of the nature of data. Note that many database vendor provides JDBC driver. These driver implements JDBC API and also has required code to establish connection to the specific database. Just before starting import procedure, Sqoop make use of JDBC so that to understand the table that it is going to import, it accesses entire column list along with its data type.
File Format
Sqoop reads the data from other data store and dump into its own format. It is capable of importing the data into following file formats –
- Text files are the very well representation of data in human readable format. It is of the simplest structure and platform independent.
- Processing data through text file is very good. However it has one drawback that it cannot hold binary fields such as they cannot hold binary fields. To handle this we have Sqoop’s SequenceFile-based format and Sqoop’s Avro-based format. Both these format provides the most precise representation possible of the imported data.
Generated Code
When we write data contents to the HDFS database table format then at that time Sqoop provides a file that gets written to local directory, known as widgets.java file.
- Sqoop can leverage this generated code in taking care of deserialization of table specific data from the database source before actually writes to the HDFS
- We have the flexibility of specifying class-name and other code-generation arguments.
- If we are dealing with records imported to SequenceFiles then it is expected that we will be using generated classes to deserialize data from the SequenceFile storage.
- It is possible that we can work with text file based records without using generated code but Sqoop’s generated code is able to handle some tedious aspects of data processing for us.
8.4 Import And Export in Sqoop
Sqoop Import
Now we are familiar with the fact that Sqoop performs an import by executing a MapReduce program. Let us have a closer look out of this process.
Divide the query into multiple nodes so that to get the efficient import performance. This is actually being done by making use of splitting column. By making use of Metadata of the table, Sqoop does a guess work of good columns for splitting of table. If there is any primary key exists then minimum and maximum value of primary key get fetched then it is being used in order to determine query that needs to be issued to every map task.
It is always a best practice to make sure that if a process updates existing row of table then it should be disabled while importing. Sqoop architecture will give you an option to choose from available multiple strategies to perform an import process. One thing to be noted down that few database provides specific tool to perform data extraction quickly.
Handling Large Sized Data in Sqoop’s import
Handling large data is another big challenge in Sqoop’s import. Large Objects are mostly stored externally from their rows (Database table represents as an array of rows with having all the columns in a row stored adjacent to one another, while large objects are normally held in a separate area of storage and the main row storage contains an indirect references to the large objects). Large data is not directly stored in table’s cell but its reference.
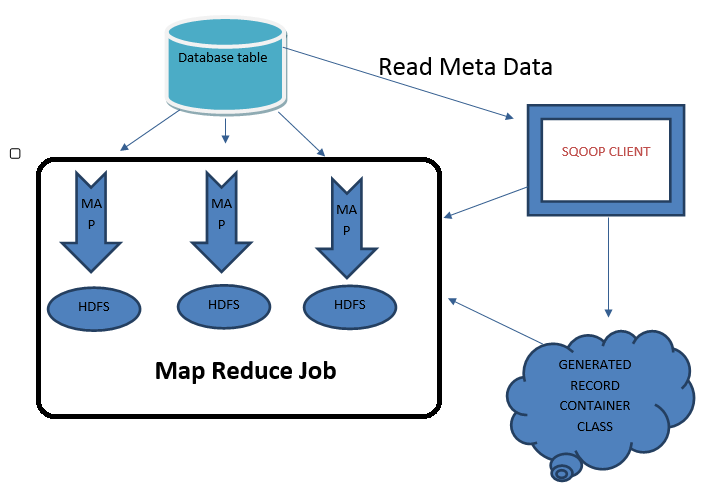
Let us have a look at below diagram and we will see the Sqoop’s import process. You will also find that Sqoop client collects the Metadata information from Database table. Also notice that there is Generated record container class that communicates with both the Sqoop client and MapReduce job. This entire process flow is a typical Sqoop’s import process. Many database provides capability to store huge sized data into a single field. Depending on the type of data, it is being stored in types as:
- CLOB
- BLOB
Sqoop provides a very good platform of processing large and complex data and finally to store into HDFS. Sqoop does the efficient processing by doing an import of large file object into separate file known as LobFile. LobFile has capability to store a record which is of huge size. So this way every record in a LobFile contains single huge object.
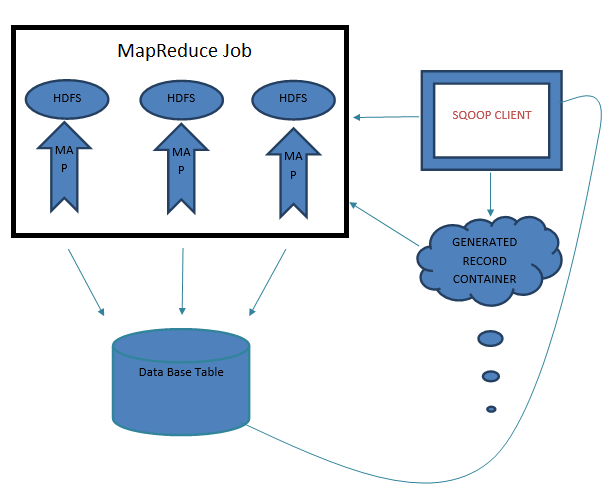
Sqoop Export
We import data from remote database and then process it through HDFS, performs all sorts of calculations and parallel computing, and finally need to load it back to the remote database. This loading back comes under exporting. Have a look at the below delimiters in Sqoop –
Escape Sequence with Description
\b | Backspace |
\n | Newline |
\r | Carriage return |
\t | Tab |
\' | Single quote |
\" | Double quote |
\\ | Backslash |
Let us have a look at the diagram of Sqoop’s export process that also explains that the Sqoop uses MapReduce to implement Parallel execution.
8.5 Sqoop – A Practical Approach
Suppose we have a datafile that contains a Product information in mysql table ‘Product’.
- Code to import the table
% sqoop import --connect jdbc:mysql://localhost/<<path>>
--tableProduct -m 1
Here “m 1” specifies that we will be having only a single file in HDFS and Sqoop should use only a single map task.
- To inspect the file’s contents
% hadoop fs -cat Product/part-m-00000
1,abc,2087,0.14,2014-05-10
2,xyz,3015,0.19,2014-04-14
…..
- To export the data back to mysql
% sqoop export --connect jdbc:mysql://localhost/<<path>> -m 1 \
> --table Product --export-dir /user/<<path>>
- To verify that the export worked by checking MySQL:
% mysql<<path>> -e 'SELECT * FROM Product'