
Data and information
It has become customary to define data as raw facts! So we shall not deviate from that tradition. Data is raw facts. Facts about people, Facts about life, Facts about the things that people do. It can be quantitative. Or it can be qualitative
Qualitative | Quantitative |
|
|
|
|
|
|
 You buy chocolates from Walmart, for you it is just another purchase. But for Walmart every purchase is a valuable piece of information. Your purchase of chocolates becomes a line in their massive data analysis (the latest hype word for this is Big Data more on this in another tutorial).
You buy chocolates from Walmart, for you it is just another purchase. But for Walmart every purchase is a valuable piece of information. Your purchase of chocolates becomes a line in their massive data analysis (the latest hype word for this is Big Data more on this in another tutorial).
Here is another customary diagram:

Here is one example where what goes in is not the same as the one that comes out! Data in, information out!
The customary definition of information is processed data. When you process data it becomes information.
Who will use the data
As you will realize while data is the same for everyone, information could be different to different people. What I consider as information may not be valuable to you as information.
For example, a supermarket branch manager would be interested in the number of units sold per each item, items that are bought together frequently (market basket analysis) etc.
While a product manager at the head office of the super market would want to know, the times and seasons in which the product is sold at high quantities.
This is because the purpose of each person’s use would be different. One would want to increase sales in his own branch. May be he would put together items that are bought together. For example if pampers and beer are bought together – he might put a beer shelf next to the pampers shelf or vice versa.
So before you process data – the important thing you must understand is who will be using the data and for what purpose.
In the Beginning
So in order for the data to be processed two things must happen. One data must be captured. Two it must be stored.
Data Capturing
The systems that capture data are called OLTP systems – Online Transaction Processing Systems. The have fancy screens which capture data just like the one below:
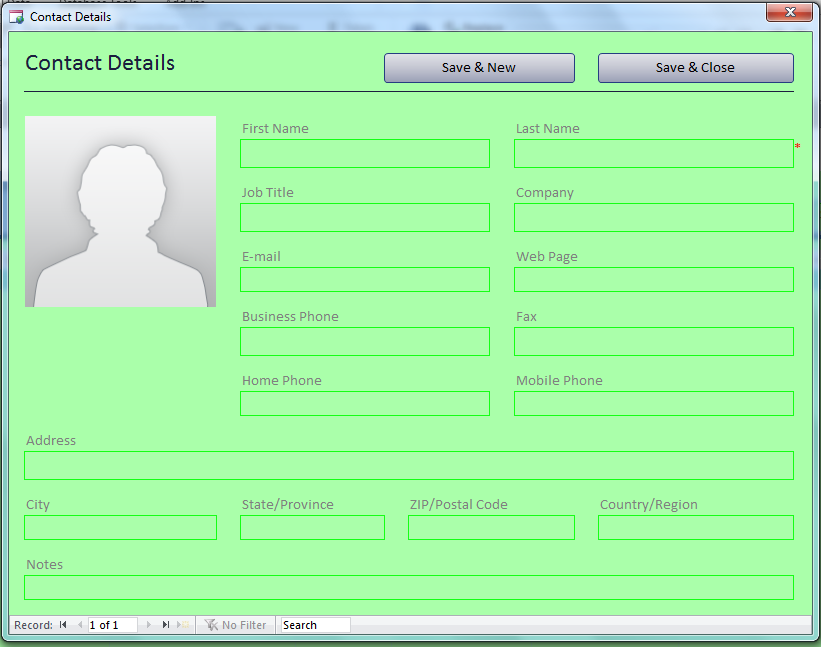
A simple Data Entry screen from Access
In the olden days people were using ledger books and other printed material to record data manually. Writing the details by using your pen. Off course you had to allocate a huge storage area or room or in some cases an entire warehouse to store those ledger books. Then came the typewriters didn’t change much – except that the writing was much readable now! The warehouses were still needed.
Then came the computers. They changed everything. It changed the way we capture data. It even changed the way we do business (see the practical application section for an example). Since it had different ways of handling data tasks that were not previously possible now became possible. For example someone can get a bank loan using the name John Mark in New Mexico and then runaway to Boston and change his name to Paul Walker to get another loan (assuming that he somehow has got a fake social security number too!). Since he still has the same face an image matching software can compare the images and figure out that he already has a unsettled loan in New Mexico. To do this we must first take photographs of the those who take bank loans and more importantly store them somewhere it can be used in the future.
The computers helped us to get rid of the ledger books. And the warehouses that was used to store them. And lay off the store keepers who were watching over those warehouses.
Data Storage
Since large amounts of data had to be captured it created an obvious problem. How and where do you store them?
The initial idea was to store them in flat files. These are called flat because they are one dimensional – as opposed to the two dimensional ‘relations’ or ‘tables’ that we are about to meet later.
Click here to see a simple employee flat file.
So the idea was simple. You had data entry programs that asked the users to enter details. And there were flat files which were ready to store them. The data entry programs – or applications – wrote the data it captured, into those files.

The dark side of file storage
While being a good start, the file systems had a lot of problems. What I have showed you above is just one file with a few records for demonstration purposes. Imagine a huge company. With a lot of employees. A hundred thousand perhaps. All that hundred thousand records would be there in this file. There would also be other files. For example whenever salary is paid to an employee that needs to be recorded too. So an Employee Salary file. If a staff gets a loan from the office then that has to be recorded too. So a staff loan file. So it is starting to get complicated.
What if the details about individual customers should also be recorded? Customer file. What if each time a customer makes a purchase that also needs to be recorded? Customer-Purchase file. You may need files to cater to an entire customer relationship management system (CRM).
So other systema are making it really complicated. What if there is a branch network each branch with its customers, employees, stocks that needs to be recorded and linked together. It makes things really really complicated.
So the details about the employees have to appear in employee file, employee-salary file, employee loan file. So any single change needs to be done in all of them. For example if Kate Heigel gets married and becomes Kate Pitt then it has to be changed in all of these files. If you miss any one of them it might cause huge data integrity issues.
There is also a security issue. Anyone can open the files and edit the data. For example John can change Brad’s salary from 75K to 65K. No one would notice until Brad is paid and makes an issue.
There is so much repetition – technically called Redundancy – to give a simple example in my own flat file the names of the departments are repeated several times.
Yet another problem would be data integrity. If you had observed the Phone numbers are not correct. There are numbers and characters mixed together.
Concurrent access is another big issue. If John and Mark both try to view and update Brad’s salary. When John checks it, the salary is 75K. John decides to give him a 10% increment. At the same time Mark also reads Brad’s salary. Without knowing that Brad’s salary had just been changed Mark gives him a 8% increment. Now Brad might end up getting 18% increment. This problem is typically called the problem of the lost update.
So people slowly started to abandon the Flat files systems. Something new was needed. Something that would help to safeguard data integrity, avoid redundancy, provide security, provide transaction integrity. All these terms will be explained more in the future chapters.
Practical Lesson
Suppose you design a system for Staff Leave Management. Before the automation people were filling the form, getting the manager to sign the form and then were handing it over to the HR executive.
How would you design the system?
In your new system you let them login to the system, enter the details take a printout, get you’re your manger to sign the printed leave form and then give it to the HR on your way out? If you think that this is the right way – you are wrong. You simply have automated what they were doing manually. There is no value addition.
Here is the right way to design the system.
You let them login, either through their desktops or laptops or even through their smart phones, let them enter the detail and save. Their manager should get either a mail or text message alert that somebody is waiting for him to approve his leave. It should have a link to the approval page. The manger clicks the link, puts the logon details and approves the leaves. Then that information is passed onto the HR department.
Exercises
- Design a employee salary system.
- Decide what information is needed to be captured in each file.