
1.1 Introduction
In the last chapter we looked at tables. In this chapter we are going to see how they fit the big picture.
1.2 Relational Model
Intro
‘It is not good for a person to be alone’ – while this is said of people being alone it is equally true of tables being alone. You can hardly ever create a system with a single table. You need a lot of them. Several thousands of them in some complicated systems. But the problem is how do you get all these tables to work together?
If you have two believers you have an organization, if you have three believers you have two organizations! The moment you put people together they start creating problems! IT is the same with tables. So you need some ground rules, establish some ways in which they can peacefully coexist and work towards a common cause.
These ground rules are called the relational model.
Relational Model
Relational Model explains how each table and thereby the data in it relates to each other. To understand this in the correct context let us revisit some of the problems we had when we had flat file systems.
1. If you can at one place you have to change everywhere.
2. You have to keep the same data in many places.
3. It must preserve data integrity – the same data must not be there in different places with different values
So in the new magic portion should somehow help us to keep data in a consistent way preserving the integrity.
Explaining this from a practical perspective you have a customer who buys a product from an outlet in Lowell. To record this transaction you need to read, insert or update many tables.
1. Customer - he makes a purchase
2. Product - the quantity of the particular product he buys must be deducted from the stock
3. Outlet - the above quantity mentioned must be deducted from the particular outlet in Lowell
4. Receipts - the payment taken from each customer is recorded here
Customer Table
Name | Age | Sex |
|
|
|
|
|
|
Product
Product | Unit Price | Weight |
|
|
|
|
|
|
Location
Location | ZIP Code | Capacity |
|
|
|
|
|
|
Receipt
Receipt Amount | Payment Mode | Amount |
|
|
|
|
|
|
(While in reality there could be many fields to these tables I have only selected a few for demo purposes)
So you will need at least 4 tables to keep all these data. Now if you look at the receipt table (by the way - on naming conventions – it is a good practice to use a singular noun – product not products) it has an important data missing. You need to keep customer information there if not we will not know who paid what.
Here is how the new set of tables will look like:
Customer Table
Name | Age | Sex |
|
|
|
|
|
|
Product
Product | Unit Price | Weight |
|
|
|
|
|
|
Location
Location | ZIP Code | Capacity |
|
|
|
|
|
|
Receipt
Customer | Receipt Amount | Payment Mode | Amount |
|
|
|
|
|
|
|
|
(remember that this set of tables needs refining which will be done in upcoming chapters – especially when we study normalization)
So we see a relationship in the making. The receipt table relates to the customer table. If I might slightly change the diagram without showing the fields it will look like below:
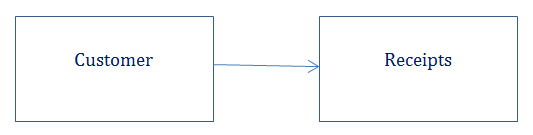
This way of tables relating to each other is called the relational model. Before we look at some examples we will look at constraints.
Constraints
To maintain the integrity of the data the human race came with a brilliant idea. Of introducing constraints. Constraints were introduced as a way of limiting what kind of data can be put into these tables.
Null Constraint
The most simplest constraint. The null constraint. If you have it on the DBMS will always ask you to put some data into that particular field. For example usually in the customer table you must make the
customer name not null
spouse name nullable since not everyone will be married
Unique Constraint
You remember when there were two Roberts the trouble it caused? And oh not to mention their girlfriends. So we called one as Bob and the other as Rob. Same with tables. Some fields must be unique so that the DBMS can refer to them uniquely.
As the Bob example explains we cannot have name as a unique key. So many Roberts. So we need to introduce something else as unique. There social security number or passport number will be a good idea.
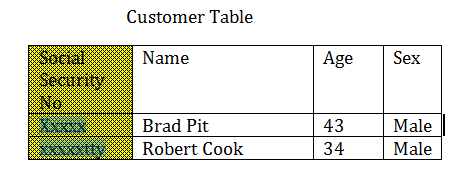
Now we have our unique Key.
Primary Keys
I am taking you step by step to understand the concepts from the simpler to the more complex ones. The primary keys are almost the same as the Unique Keys. But the difference is that there could be many unique keys in a table (Social security no, passport no etc.). But there could be only one primary key. The usual way of doing that would be to introduce another new field - usually almost 100 % of the time it is a numeric field – and use that as the primary key.
Another difference between unique keys and primary keys is that the values for unique keys can be null – while a primary key should always have values.

So now we have our primary key.
Referential Constraint aka foreign keys
In the example we gave above how do we make sure that in the receipt table somebody by mistake enter a customer who is not there in the customer table? Referential Constraints or Foreign Keys are there to make sure that this doesn’t happen. It is a way to enforce that whoever the customer you put in the receipts table should first exist in the customer table.
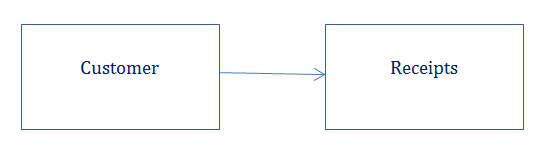

To create a foreign key first there must be a primary key in the parent table. If there is no Primary key we will not be able to add anything as foreign key. This is understandable as it would cause confusion for example let’s say you add the customer number as a foreign key to a child table. For the same customer number if there are multiple entries in the parent table then we will not know which one is referred to. So the only way of stopping this is to say that it should be a primary key in the parent table – to make sure that it is unique.
There are many other constrains. One thing that might be worth mentioning is the value constraint – where in a field like sex – you allow people to put only male or female otherwise they may come with answers like – sex? at least one in a week!
A note on null
A null is never equal to anything. It is not unequal to anything also! So
If you issue a SQL statement saying
SELECT *
FROM employee_table
WHERE married_Date = NULL
It will not return any rows – even if there are rows where the table has employees who are not married i.e. married_date is null. So the correct way of doing that would be
SELECT *
FROM employee_table
WHERE married_date IS NULL.
The 12 commandments aka codd’s 12 rules
When DBMS were starting to emerge Edgar F Codd wrote a set of rules in the computer world magazine which has become a defacto standard – and now taken for granted and long forgotten. Here they are:
1. Information Rule All the data must be stored and represented as values in tables.
2. Guaranteed Access Rule – all data must be accessible. It should not be the case where certain deep parts of the pot are not accessible.
3. Systematic treatment of null values – DBMS must allow values to be null. You can leave a cell ‘blank’ null.
4. Active Online Catalog – as I explained in the meta data section, the DBMS must maintain an active catalog of its data. And this catalog must be queriable in the same way the main application data is queried.
5. Comprehensive Data Sub Language Rule – the DBMS should support a query language that
1. Has a proper syntax.
2. Can be used directly and can be embedded within other programming languages, applications and tools.
3. Has
a. DML – data manipulation language – the commands that are put to manipulate the data
b. DDL – the commands that are put to create/edit or delete the underlying structures such as tables, Indexes, Views etc.
c. DCL – Data Control Language – Commands used to grant and revoke security privileges etc.
6. View Updating Rule all views that can be updated theoretically must be updated by the system.
7. High Level insert, update and delete – the DBMS to support one row of insert or update or delete rather a set of data. The DBMS must be able to process a set of data rather than processing a record one by one.
8. Physical Data Independence – changes to the physical level should not affect the logical level i.e. the applications.
9. Logical Data Independence – changes to the logical structures such as tables should not cause changes to the applications which are using them.
10. Integrity independence – we must be able to defined the integrity constraints in the database itself and they must be viewable through the catalog (meta data). There is no need to define the integrity constraints in the application itself.
11. Distribution independence – the users must not be aware or feel if the data is taken from different locations.
12. Non Subversion Rule – if the DBMS provides a low level interface to access one record at a time – it must not be possible to bypass security or integrity constraints.