
Starting with Hadoop and Hadoop Program Building
3.1 Apache Hadoop
Hadoop is Apache Organization’s Proprietary framework, However it is an open source product and available to download from internet.
Let us first visit all its versions from the beginning –
2007
0.15.1
0.14.4
0.15.0
0.14.3
0.14.1
2008
0.19.0
0.18.2
0.18.1
0.18.0
0.17.2
0.17.1
0.17.0
0.16.4
0.16.3
0.16.2
0.16.1
0.16.0
0.15.3
0.15.2
2009
0.20.1
0.19.2
0.20.0
0.19.1
0.18.3
2010
0.21.0
0.20.2
2011
1.0.0
0.22.0
0.23.0
0.20.205.0
0.20.204.0
0.20.203.0
2012
1.1.1
0.23.5
0.23.4
1.1.0
1.0.4
0.23.3
1.0.3
1.0.2
1.0.1
0.23.1
2013
0.23.10
2.2.0
1.2.1
0.23.9
0.23.8
1.2.0
0.23.7
1.1.2
0.23.6
3.2 Hadoop Requirement
Hadoop is made to work on large data sets and it processes big data in considerably less time with its underline architecture and massive scalable capability. This definitely means that the system that is running Hadoop should be equipped with good storage and processing power. While setting up on your own machine for the practice purpose it is good to have –
- 4+ GB RAM
- 10+ GB free HD storage
- Processing power 2+ GH
Make sure to have the following software readily available with you before beginning the installation –
- Hadoop download setup
- JAVA JDK 1.6
- Linux Operating System (Red Hat, Ubuntu etc.)
- VMware Player (In case want to run Linux from Windows)
3.3 Get Hadoop in your PC
Hadoop works on Linux machine. So there are two ways to start with Hadoop, either keep Linux as operating system in your machine and install Hadoop or install a VMware Player in your windows operating system and create a virtual machine for Linux.
Once you have VMware player installed and Linux operating system is setup in it, then open it and click on Play Virtual Machine
Create a folder in Linux and paste JDK and Hadoop installable in it.
Open the Terminal from Linux (go to Applications->Accessories->Terminal).
In the root, create one private directory for Hadoop so that you can use it for all Hadoop related operations.
Begin with JAVA JDK installation
Using ‘cd ‘, go the folder location where setup for JDK is copied.
Use the command ‘sh’ followed by the installable file name, run it and the JAVA will get installed.
Now the Hadoop installation
Use the command ‘tar xzf’ followed by Hadoop zip file (Hadoop installable file for Linux), run it and Hadoop installation will begin.
There is one hidden file .bashrc in the home directory of Hadoop installation. We need to set environment specific variables in this file.
export HADOOP_HOME=<<Set the Hadoop home directory>>
export JAVA_HOME=<<set the JAVA directory>>
Set JAVA_HOME in Hadoop-env.sh file.
Now we need to perform some site specific configuration. Setting up configuration is one of the most important activities to prepare your system. These web sites provide much of administrative and monitoring capability over Hadoop ecosystem. These sites are:
core-site.xml
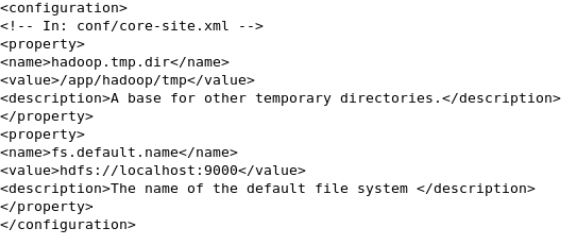
hadoop.tmp.dir sets the path for temporary directory
fs.default.name sets the url for the Name Node.
mapred-site.xml

mapred.job.tracker sets the url for Job Tracker
hdfs-site.xml

dfs.replication lets you specify the replication of Data Nodes in the Hadoop cluster. We have set this up as 1 for a standalone single machine.
Till now we have seen what Hadoop is, How it works and its underline architecture. We have also seen the installation and setup part on an individual machine. Let us move toward to the next chapter and begin with interacting with Hadoop and we will develop some application in it.
3.4 Design Control Flow
We have understood Hadoop and its components, seen the basic installation steps and configuration setup process. It is time to dig up little more and understand the programming structure. Let us begin interaction with Hadoop with this example. Suppose we have three files and all these three files contain name information of various companies. Also the name of these companies is not unique across three files but repeating. Our objective is to find out the value of total count of company name appeared in these three files. Here is how the files are looking –
File1 | File2 | File3 |
Micromax | Samsung | Nokia |
Nokia | Motorola | Micromax |
Apple | BlackBerry | Sony |
Sony | Micromax | LG |
LG | Apple | HTC |
Output should be –
Company Name | Total Count |
Apple | 2 |
BlackBerry | 1 |
HTC | 1 |
LG | 2 |
Micromax | 3 |
Motorola | 1 |
Nokia | 2 |
Samsung | 1 |
Sony | 2 |
We will begin our journey to understand Hadoop with this word count problem and we will try to understand Map Reduce programming model. To begin we will do this program through JAVA until we understand languages built over Hadoop.
We will address this problem in two processes:
· Mapper Phase
· Reducer Phase
In Mapper Phase initially all the information gets separated into token of words then we form a key value pair with all these words. where key looks as:
{Word, count}
Considering our example the key value pair would be as:
{Micromax, 1}
{Nokia, 1}
{Apple, 1}
{Sony, 1}
{LG, 1}
{Samsung, 1}
{Motorola, 1}
{BlackBerry, 1}
{Micromax, 1}
{Apple, 1}
{Nokia, 1}
{Micromax, 1}
{Sony, 1}
{LG, 1}
{HTC, 1}
In Reduce Phase grouping happens and all the keys get grouped together. All the 1s from similar words get summed up together. After this aggregation the key value pair would look as:
{Apple, 2}
{BlackBerry, 1}
{HTC, 1}
{LG, 2}
{Micromax, 3}
{Motorola, 1}
{Nokia, 2}
{Samsung, 1}
{Sony, 2}
The flow of the program is such that, first the Mapper program gets executed and performs the tokenization, which means to split words and to form initial key value pair, followed by the execution of Reducer program. In the Reducer program the words get aggregated and similar words get grouped and associated group count gets stored.
This is a very standard process of Hadoop to write a Map and a Reduce program to complete the task. Mapper and Reducer logic gets vary as per the problem description.
JAVA is one way to achieve this task. However there are other languages some built over Hadoop and some other independent languages that can help us in building Map Reduce programs.
3.5 Mapper
The Mapper program sets the pairs of key (word in our example) value (total count in our example)to a set of intermediate key/value pairs. Maps are basically some individual tasks that convert input set into an intermediate record.
As we know that the files get split into blocks and the blocks are replicated in the Hadoop cluster. Note that the Input Format generates the Splits. InputFormat classes are subclass of FileInputFormat. FileInputFormat'sgetSplit function generates a list of Splits from the List of files defined in JobContext.
As a standard practice, if you have n nodes, the HDFS will distribute the file to total n nodes. FileInputFormat is actually an abstract class that defines how the input files are read and will get spilt. Along with this, it also Selects files that will be used as input and it defines Splits that breaks a file into tasks. As per Hadoop’s basic functionality, if there are n splits then there will be n mappers.
When you begin a Map Reduce Job, internally Hadoop takes care of the most efficient execution. Hadoop assigns a node for every split. Hadoop performs execution of mapper on the nodes where the block resides.
Let us understand the function of following –
JobConfigurable.configure | Mapper can access the Job Configuration and initialize themselves |
Closeable.close | In the same way this method is used for the de initialization |
Hadoop framework calls Map for each key value pair in the Split for that task. | |
JobConf.setOutputKeyComparatorClass | A Comparator, To control the grouping explicitly |
JobConf.setCombinerClass | A Combiner, To perform local aggregation of the intermediate output, this will assure only the relevant data gets passed from Mapper to Reducer |
Partitioning happen over every Mapper and its outputs gets assigned to Redecers. | |
Custom Partitioner | To give a control to Users to decide which record should go to which Reducer. |
SequencesFiles | To store the intermediate outputs |
Suppose a job has no Reducer in Hadoop framework, then in this case the output from the Mapper is directly written to the FileSystem, and grouping of keys does not happen.
3.6 Reducer
Reducer reduces the records received from Mapper in Hadoop framework. JobContext.getConfiguration() method helps Reducer build the capability to access the Configuration for the job. Here is the very basic functionality of Reducer:
In the first step Reducer performs a copy of output received from Mapper. For this copy Reducer uses the Hyper Text Transfer Protocol.
Hadoop framework merges Reducer inputs by keys for the cases where Mappers possesses the same key.
The above mentioned two phases takes place at the same time concurrently.