8.1 Use of aggregate functions
Sometimes the user needs to view the summary of the data. The summary contains aggregated values useful for analyzing the data. SQL Server provides aggregate functions to generate the summarized data.
The view of the summarized data in different groups is based on the specific criteria. Depending on the requirements, users can calculate the summarized values of a column based on a set of rows. The aggregate functions summarize the values of the column or a group of columns. The syntax for the aggregate function is as shown below:
SELECT aggregate_function ((ALL|DISTINCT) expression) FROM table_name
Where,
ALL specifies that the function is applied to all the values in the column.
DISTINCT specifies that the function is applied only to the unique values in the specified column.
expression specifies the column or expression with operators.
The different functions for summarizing the data are as follows:
1) Avg(): It returns the average of the values in the expression.
The following query is used to return the average value from the employee1 table.
select ‘Average Rate’ =avg(hourrate) from employee1
The output of the query is as shown below:
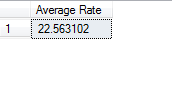
2) Count: It returns the number of values in an expression. It can be all or distinct.
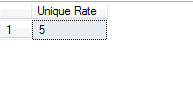
The following query is used to return the unique rate from the employee1 table.
select ‘Unique Rate’=COUNT( DISTINCT hourrate) from employee1
The output of the query is as shown below:
The count() function also accepts the ( * ) as the parameter, but it returns the counts of the rows returned in the query.
3) Min(): It returns the lowest value in the expression.
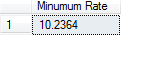
The following query returns the minimum value from the rate column of the employee1 table.
select ‘Minimum Rate’=Min(hourrate) from employee1
The output of the code is as shown below:
4) Max(): It returns the highest value in the expression.
The following query returns the maximum value from the rate column in the employee1 table.
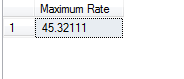
select ‘Maximum Rate’=Max(hourrate) from employee1
The output of the code is as shown below:
5) Sum: It returns the sum of total values in an expression either all or distinct.
The following query returns the sum of the unique rate values in the employee1 table.
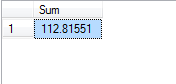
select ‘Sum’=SUM(hourrate) from employee1
The output of the code is as shown below:
8.2 Grouping Data
Consider a situation where the user needs to view data matching the specific criteria together in the result set. The data can be grouped by using the GROUP BY, COMPUTE, COMPUTE BY clauses along with the SELECT command.
GROUP BY
The GROUP BY clause summarizes the result set into groups, defined in the result set along with the aggregate functions. The HAVING clause restricts the result set to produce the data based on the condition. The syntax of the GROUP BY clause is as shown below:
SELECT column_list FROM table_name
WHERE condition [GROUP BY [ALL] expression [, expression ]
[ HAVING search_condition]
Where,
ALL is used to include the groups that do not meet the condition.
expression specifies the column name or expression on which the output is computed.
search_condition is the expression on which the result set id developed.
The following query returns the minimum and maximum of the leave hours for different type of roles where the employee can go on leave for the value greater than 60.
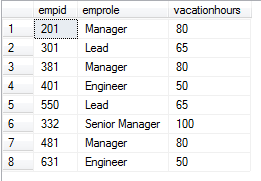
Consider the empholiday table consisting three columns as empid, emprole, and vacation hours. The values in the table are as shown below:
The query for retrieving the use of the GROUP BY clause is as shown below:
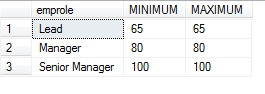
select emprole, ‘MINIMUM’=min(vacationhours), ‘MAXIMUM’=max(vacationhours) from empholiday where vacationhours > 60 group by emprole
The output of the query is as shown below:
COMPUTE
The COMPUTE clause is used with the SELECT statement for generating the summary of rows by using the aggregate function. The GROUP BY clause does not produce individual table rows in the result set. The COMPUTE clause generates individual data rows from the table.
The syntax of the COMPUTE clause is as shown below:
SELECT column_list FROM table_name
ORDER BY column_name
COMPUTE aggregate_function (column_name)
Where,
ORDER BY column_name is the name of the column by which the result is stored.
COMPUTE aggregate_function is used to specify the row aggregate function from the list
column_name specifies the name of the column for which the report is displayed.
Consider the department table which consists of five columns as DeptID, Empname, designation, Leave Hours and Sick Hours.
The table consists of the following values.
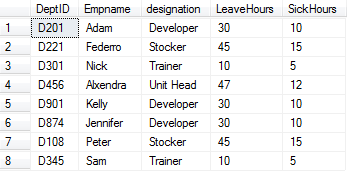
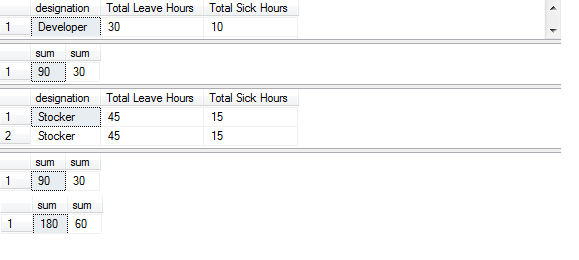
The query using the compute clause for calculating the total leave hours and sick hours is as shown below:
select designation, ‘Total Leave Hours’=LeaveHours, ‘Total Sick Hours’=Sick Hours’ from deptdetails
where desgination in (‘Developer’,’Stocker’)
Order By designation, LeaveHours, SickHours
Compute sum(LeaveHours),sum(SickHours)
The output of the query is as shown below:
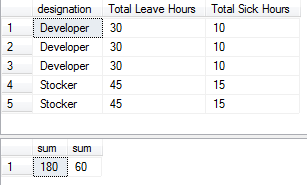
COMPUTE BY
The BY clause is used to specify the name of the column by which the data is grouped.
The syntax for the COMPUTE BY clause is as shown below:
SELECT column_list FROM table_name
ORDER BY column_name
COMPUTE aggregate_function (column_name)
[BY column_name]
Consider the same example, but the user wants to use the COMPUTE BY clause to calculate the subtotals of the Leave Hours and the Sick Hours.
The following query using the COMPUTE BY clause is mentioned.