
Let us have a look at the Architecture of MongoDB that includes sharded cluster.
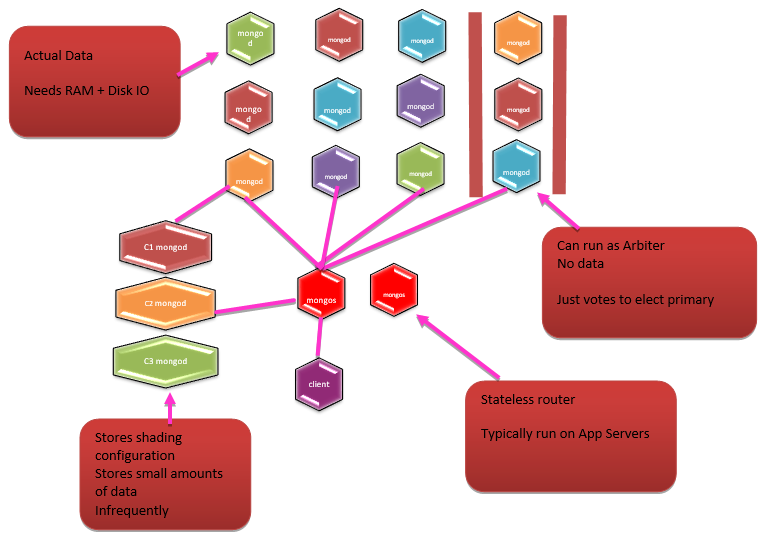
mongod is daemon process (primary process) in MongoDB system. It does following –
- Take care of data request
- It manages access to data
- It performs management operations at background
mongos is routing service of MongoDB shard configurations. It does following –
- Process queries from application layer
- Determines the position of data in sharded cluster
- It is a stateless router
- It behaves like mongodb
- Plays an import role by forwarding request of client to correct shard server
As we can see in the diagram that there are 3 config servers (C1, C2, C3). Ideally each config server should be a separate machine. When you are having multiple sharded clusters then you should have group of config servers to support each cluster.
A replica set is group of mongod processes that maintains same data set. It provides redundancy in order to provide high availability.
A shard is actually a replica set which contains a subset of the data for sharded cluster. Together all the shards make up the entire data set for cluster.
Arbiter is the mongod instance, it is a part of replica set but does not contain data. Here are its characteristics –
- Participates in elections so that it can break ties
- In cases where your replica set has an even number of members then add an arbiter
- Does not require dedicated hardware
- Can be deployed on an application server, even on a monitoring host
In a production cluster we have to make sure that our system is high available and data is redundant. Ideally production cluster should have following components:
Config Servers
Config Server stores the metadata for sharded cluster, they are the special mongod instances. Note that config server uses procedure of two phase commit in order to insure:
- Immediate Consistency
- Reliability
They do not RUN as replica set. All config server should be available for:
- Deploying a sharded cluster
- Making changes on cluster metadata
Production sharded cluster contains exactly 3 config servers. Here are the reasons for having 3 config servers:
- If our sharded cluster has only a single config server then it would become a single point of failure.
- In any case if config server is inaccessible then entire cluster would not be accessible.
- In the event, you are not able to recover data on config server then the cluster would become inoperable.
Other important thing to understand is that each sharded cluster should be having its individual config server. We should never ever use the same config server for separate sharded cluster. Config server stores metadata in config database. The “mongos” instance do the job of caching this data and use it for the purpose of:
- Route Reads
- Write to Shards
These are the following cases when MongoDB writes data to the config server:
- At the time of creating splits in the existing chunks
- While migrating chunks between shards
The following are the cases when MongoDB reads data from config server:
- New mongos starts for first time or an existing mongos restarts
- After doing a chunk migration, note that in this case mongos instance does an update of itself so that to have new cluster metadata
I would like you to pay attention to the fact that MongoDB also makes use of config server in managing distributed locks.
Now the biggest question is about the availability of config server. Let us revisit this by taking the cases of number of server become unavailable:
- If 1 or 2 config server become unavailable then cluster’s metadata become read only. In this cases we can very well perform read and write from shards. However, no chunk migration or the splits will take place until all the 3 servers are available.
- If all 3 config servers are unavailable then we can still use the cluster if we do not restart mongos instance until after config server become accessible again. Note that if you restart the mongos instance then before config server available then mongos would not be able to route read and write operations.
It is our responsibility that config server is always available and remain in contact. Hence backup of config server becomes very critical. Note that normally the data that config server has is comparatively of lower size than the data available on cluster. This means it is an easy task to take the back up of config server.
Shards
2 or more “replica set” are known as “shards”. MongoDB is a high available in a way that it would always be available for processing; absolutely no loss of data and no loss of server to trigger operation. Replication introduces redundancy and also increases data availability. With having many copies of data present on separate database servers, replication definitely protects database from loss of single server. It also allow us to recover from the service interruptions and hardware failure. With these additional copies of data, we can dedicate one for disaster recovery or backup. However in some cases you can definitely use replication to do increase in read capacity. As we know that Clients have ability to perform read write operations on different servers. We can also maintain copy in separate data centers to increase locality and availability of the data for the purpose of distributed applications. A replica set is the group of mongod instances that actually host same data set. There is 1 mongod which primarily receives all write operations. All other secondary instance apply operations from primary to have the same data set. If primary is unavailable then replica set would elect a secondary to become primary.
Query Routers
They are one or more mongos instance. The mongos instance is the router for cluster. Typically you will find deployments has one mongos instance on each application server.