
5.1 Writing Complex Pig Programs
With its high level data processing power on top of Hadoop, the Pig Latin languageprovides programmers a veryinsightful way to specify data flows. Pig supports schemas in processing structured, unstructured and semi structured XML data.
Pig program is consists of sequence of transformations, that work on input source data and produce the required output. These sequence of transformations are known as a data flow, finally this data flow gets converted into an executable presentation translated by Pig execution environment.
This is what happens inside the Pig execution environment –
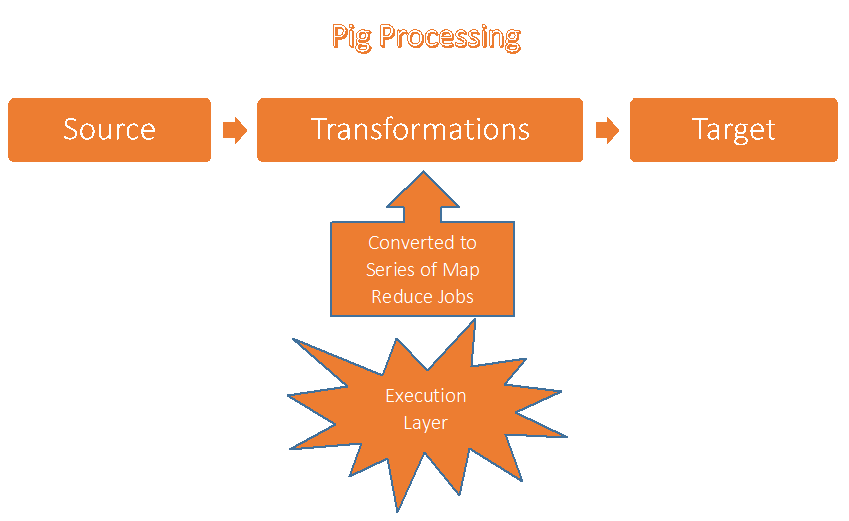
We can see that Pig convert the written program into series of Map Reduce job. Writing Map Reduce Job is Pig's strongest ability, with this it process Tera Bytes of data using only very few linesof code. As we know that Pig was developed for the people of Yahoo to make them enable to perform mining on huge data. Pig makes it possible to do write very simple to complex programs to address simple to complex problems.
We understand that Pig-
- Supports programmer an ease of writing a query
- Providesseveral commands for analyzing the data structures in your program
- Designed to be extensible
- Processing is highly customizable
- Performs batch processing of data
A very strong utility of Pig programming is writing UDF (userdefinedfunction). All these UDF interactclosely with Pig’s operators. The biggest benefit of using UDF is its reusability, once a UDF is defined it can be used anywhere and any number of times.
5.2 User Defined Functions in Pig
We explained in previous section that in Pig we can write User Defined Function to achieve a desired functionality. These functions are like functions written in any other language. We can understand it in a manner that Pig provides lot of inbuilt functions those addresses lot of requirements andproblems but that definitely cannot cover everything. So, for these additional requirements we have Pig's user defined function utility. These functions can be written in lot of languages including Java and Python.Let’s create a User Defined Function to filter the records by first quarter of the month. Here is the Pig program we have –
First_Quarter_Data = FILTER Year_Data BY
(Month_Num == 1 OR Month_Num == 2 OR Month_Num == 3);
We are expecting a user defined function so that it can be directly used without writing each month name number of quarter 1 of the year, So the program shoud be like -First_Quarter_Data = FILTER Year_Data BYQuarter_Data(Month_Num);
We will create this user defined function with the name Quarter_Data in JAVA as:
importjava.io.IOException;
importjava.util.ArrayList;
importjava.util.List;
importorg.apache.pig.FilterFunc;
importorg.apache.pig.backend.executionengine.ExecException;
importorg.apache.pig.data.DataType;
importorg.apache.pig.data.Tuple;
importorg.apache.pig.impl.logicalLayer.FrontendException;
public class Quarter_Data extends FilterFunc {
@Override
public Boolean exec(Tuple tuple) throws IOException {
if (tuple == null || tuple.size() == 0) {
return false;
}
try {
Object object = tuple.get(0);
if (object == null) {
return false;
}
inti = (Integer) object;
return i == 1 || i == 2 || i == 3;
} catch (ExecException e) {
throw new IOException(e);
}
}
}
In order to use the new function, first we need to compile it and package it in a JAR file. Then we will notify Pig about the JAR file by using REGISTER operator. After this the function is ready to invoke.
5.3 Optimization in Pig
Implementation of optimization of any program in any language means to make sure following -
- Program should get run and completed in as minimum time as possible
- Program should use as least as memory resources to get completed
The same is true in case of Pig programming, and we need to make sure of these things while implementing efficiency and cost effectiveness of Pig programs. If you knowthe optimization of Pig program then this will definitely make a lot of difference in terms of how your Pig program is going to perform. While optimizing Pig program it matters a lot that how you build the flow of the program, what component you have chosen to work with. Always remember that Pig is not alone who is going to take part in the process, You have powerful Map Reduce architecture who is going to work along with Pig and it provides lot of flexibility for optimization. Especially when we are dealing with Big Data then it also matters what type of data we have and what is the overall data size to deal with. Here are some of the guidelines to improve the Pig programming performance -
- Input size and shuffle size has to be chosen carefully
- Map Reduce model should be optimized enough to take care of memory size and processing time in a well-defined way
- Size of the data that flows during the process flow should be as required as possible. e.g. If some data needs to be filtered then it should be done in the initial phases of the flow to avoid flowing large data. This will save the considerable amount of time of data processing
- Always remember that each and every component of Pig programming can be optimized. e.g.
- Joins
- Groups
- HDFS architecture
- Correct number of Maps and Reduces
Performance will be improved only when you have optimized architecture with combination of right component for data processing.
We will have a closer look out on Pig optimization in our subsequent chapter where we will understand in very deep the correct setup of architecture, right selection of components and some important configuration settings.